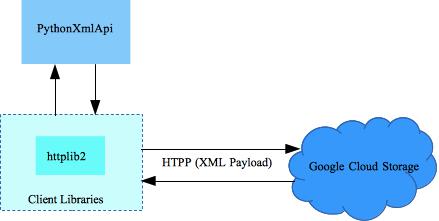
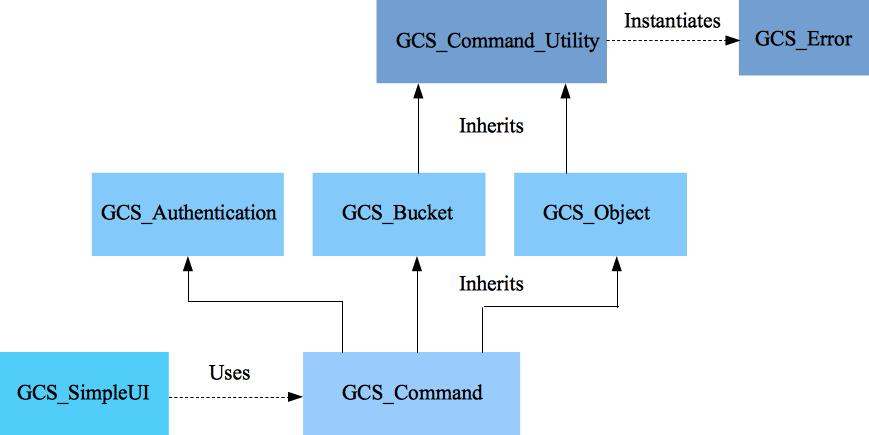
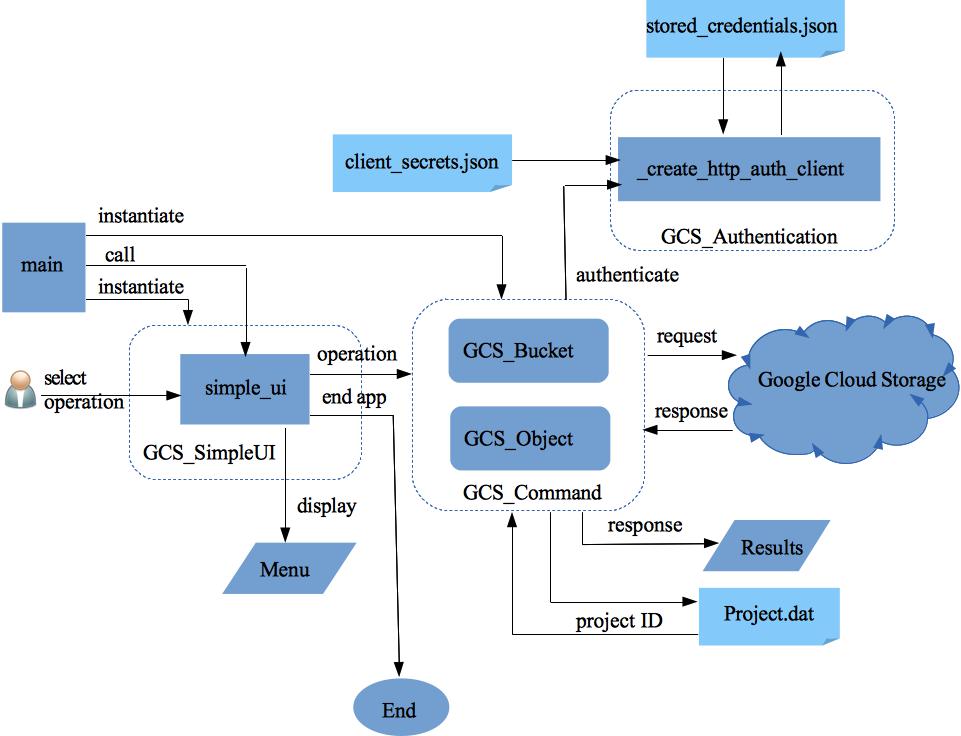
These guidelines help creating cloud ready applications and suggest best practices. Background information and relevant links are included.
The goal is to provide information that can help the transition from a desk-top or a virtual environment to the cloud.
At first, this transition can seem daunting. But, once you have mastered the details, it becomes obvious and natural how to make the “paradigm shift”.
The good news is that the rewards are great. This is because the cloud is not a fad but a solution for real world problems. Problems such as resource availability , resources utilization and provisioning , handling of peak request traffic , failure handling, cost of over-estimation , and so on.
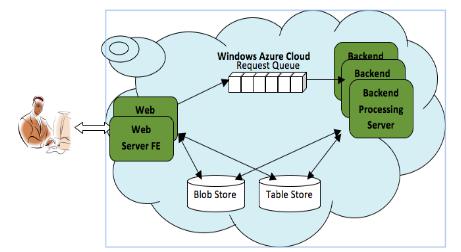
If we have to pinpoint the main architectural principle, we must say that the cloud is predicated on delivering IT services on demand. An extension of this is the concept of application as a service (usually, a REST Web service). The result is software architectures with qualities such as: elasticity, auto-scaling, fault tolerance and administration automation.
Virtualization Versus Cloud
|
Before diving into the details of the cloud environment, let’s look into the differences with virtualization. The two environments look similar but they are very different in approach and philosophy.
- Virtualization handles the physical infrastructure which supports many standard applications mainly because physical servers are converted into virtual ones without difference in architecture. Applications that run in a virtual environment scale vertically meaning that to improve their performance, for example, more resources are added to the infrastructure without direct intervention on the part of an application.
- The cloud handles the logical infrastructure such as resource management, dynamic scaling, and so on which allow flexibility, automation, and massive scaling on demand. Applications that run in the cloud scale horizontally meaning that to improve their performance, for example, more copies of an application are created and, if needed, more commodity servers are provisioned automatically using the cloud API. This scaling is dynamic and requires the intervention on the part of the application.
In virtualization and private cloud the physical infrastructure is a concern for an organization, while in a public cloud the concern is shifted to the cloud service provider. However, in private or public clouds, far reaching implications exist. For example, in a virtualized environment, applications rely on the redundancy of the infrastructure layer for transparent failover. In contrast, in a cloud environment, the applications themselves must recover from failures.
The architectural differences between the two computing environments are highlighted next.
Virtualization
The architecture follows a “hub-spoke” approach where Virtual Machines (VMs) report to a central controller or hub. This implies that there is a single “point of contention” which limits the scale that can be obtained. The following are the main characteristics:
- Redundancy. It is obtained through clustering of hypervisors for high availability. Also multiple levels of redundancy are achieved via redundant hardware components. Fault tolerance is achieved via live migration(without intervention on the part of the application).
- Scaling. This is vertical scaling where multiple backup systems in the infrastructure enable redundancy and performance improvement. These systems are expensive to build and there is a limit to the scale that can be obtained.
- State. The application state can be effectively managed on a single server. The infrastructure such as load balancer can be used to manage stateful connections.
Cloud
The architecture follows a “shared-nothing” approach or “shard” approach. This implies that VMs are independent from each other and no single point of contention exists. This allows massive scale by simply adding commodity hardware. The following are the main characteristics:
- Redundancy. Redundancy must be built in the application, do not expect it from the infrastructure. Fault tolerance must be a concern and cannot be delegated to the underlying infrastructure.
- Scaling. This is horizontal scaling obtained by adding or subtracting VMs to affect performance. In theory, there is no limit to scalability. If one machine dies it is simply replaced with a new one. The application should make use of this capability by adding or removing more VMs as needed.
- State. A cloud environment is not inherently redundant, so an application cannot rely on the infrastructure to handle state information. If a virtual machine dies, for example, an application must allow for a seamless transition.
Virtualized Environment
- Shared resources
- VM instances must report to a central hub to operate
- Failure and performance management via vertical scaling achieved through redundancy of the infrastructure layer via multiple levels of hardware redundancy
- Support for live migration to handle failure
- Stateful applications which require the infrastructure, such as the load balancer, to manage stateful connections
Cloud Environment
- Each VM instance is independent and self-sufficient
- Failure and performance management via horizontal scaling achieved through redundancy of the application layer across multiple VMs in different regions and availability zones
- Horizontal scaling at application layer to manage failures: if one application dies it is simply replaced by another
- Stateless applications that are architected to manage their own state information
- No ability to change CPU or storage capabilities in a provisioned VM instance
- VM instance must be terminated and a new one must be created with different configuration
- Instance re-imaging is not allowed– pre-defined flavors combined with self-service provisioning means an instance can be terminated and re-provisioned with the required OS image
- Data is not persistent, that is if a VM dies all data stored in its storage area is lost. If data must persist, than external (to the VM) storage must be used.
Notes
Cloud VMs can be created and deleted dynamically (through UI or command line tools).
The redundancy is an attribute of a cloud application and not of the infrastructure, as in the virtualized environment.
The cloud provides a new approach on how to design scalable, high available applications and handle failures.
The architecture of cloud applications follows the Representational State Transfer (REST) guidelines.
Traditional virtualized infrastructure generally necessitates predicting the amount of computing resources applications will use over a period of several years. If resources are under-estimated, applications will not have the horsepower to handle unexpected traffic. If over-estimated, money is wasted on superfluous resources.
However, the on-demand and automated elasticity of the cloud enables the infrastructure to be closely aligned (as it expands and contracts) with the actual demand, thereby increasing overall utilization and reducing cost.
Elasticity is one of the fundamental properties of the cloud – the power to scale computing resources up and down easily and with minimal friction. As a software developer building applications for the cloud, one needs to internalize this concept and work it into the application architecture in order to take maximum benefit of the cloud.
Best Practices
Intelligent elastic cloud architecture allows resources to be utilized only when needed. Elasticity should be an application architectural design requirement.
- Identify what components or layers in an application can be elastic
- Determine what it takes to make the components elastic and the impact on the application architecture
- An elastic application must be redundant, which is it must be designed for replication over any number of machines (virtual machines that is) in different availability zones and regions
- An elastic application must be stateless
Elasticity can be implemented in one of the following ways:
- Proactive cyclic scaling. Periodic resource scaling occurs at fixed interval (daily, weekly and so on)
- Proactive event based scaling. Resources scaling is planned in relation to specific events such as new product launch, marketing campaigns and so on.
- Auto-scaling based on demand. Using a monitoring service, triggers are issued to take appropriate actions to scale resources up or down based on metrics such as utilization of servers, network I/O and so on.
Notes
Elasticity refers to the cloud’s ability to scale. The following are examples of elastic applications:
Web Site
A service provider runs a website on the cloud. At beginning, the website runs on a single virtual machine. The site suddenly becomes popular, and more virtual machines are needed to handle the increased load. An elastic system immediately detects this condition and provisions additional virtual machines to handle incoming traffic scaling the service seamlessly.
Payment Gateway
The previous web site allows access to a payment gateway service that suddenly is overloaded by customer requests. The elastic payment gateway service is cloned as many times as needed to handle the spike in the customer requests. Elastic applications can allocate and de-allocate resources (VMs) on demand for specific application components. Moreover, an application must be stateless to allow replication and handling of conditions such as peak traffic.
The cloud infrastructure provides “unlimited” horizontal scaling. However, to take advantage of this feature, application architectures must also be scalable.
Best Practices
- Identify monolithic components and bottlenecks
- Refactor the application to take advantage of the infrastructure scalability
- Assure that the application architecture is based on loosely coupled components where components interact asynchronously and see each other as black boxes
- Design every component as follows:
- Exposes a service interface
- Is responsible for its own scalability
- Interacts with other components asynchronously
- Is stateless and stores session state information externally (in a database, if needed)
Notes
The more loosely coupled the application components are the greater and better the application scales. If components do not have tight dependencies, if one fails or is unresponsive the others continue to work.
Loosely coupled applications can be implemented using cloud messaging queue services. If a queue/buffer is used to connect any two components, it can support concurrency, high availability and load spikes.
In a web application, for example, this implies isolating the app server from the web server and from the database server.
Asynchronous applications and scaling horizontally are key cloud properties. They allow adding more instances of the same component. They also allow the design of innovative hybrid models where a few components continue to run on-premise while others can use the cloud for additional compute power and bandwidth. In this way, you can overflow excess traffic to the cloud through smart load balancing strategy.
Auto-scaling allows automatically launching or terminating compute instances based on user-defined policies, health status checks, and schedules. Compute resources are servers in the cloud. For applications configured to run on a cloud infrastructure, scaling is an important part of resource management and cost control.
An application must be able to handle hardware and software failures. Incorporate this thinking in the application architecture to make it fault-tolerant and optimized for the cloud. The following are some common failures that applications must be able to handle:
Hardware Failure
- What happens if a VM fails?
- How to recognize the failure and recover from it?
- What are the single points of failure?
- If there are master and worker servers in the system, what happens if the master fails?
Software Failure
- What happens if the dependent service changes the interface?
- What happens if the downstream service times out or issues an exception?
- What happens if the cache grows beyond the memory limit of an instance?
Best Practices
- Have a coherent backup and restore strategy and automate it.
- Build process threads that resume on reboot.
- Allow the system state to be restored by reloading messages from the queues.
- Have your app deployment process automated.
- Avoid in memory sessions or stateful user context; move related information to data stores.
- Assure application high availability by utilizing multiple availability zones.
- Fail over gracefully.
Notes
An application should be impervious to reboots that is it should be brought up and resume the previous state without any problem.
For example, if the instance on which a controller thread was running dies, it can be brought up and resume the previous state as if nothing had happened. This can be accomplished by the automated application deployment process.
If a VM fails, application traffic will be rerouted to a different machine perhaps in a different region. When auto scaling is enabled, new machines are automatically provisioned if needed. This relies on an automated deployment process.
It is the responsibility of the developer to assure that an application can be distributed.
High Availability
Regions are logically similar to data centers. By deploying an application to multiple regions, its high availability is assured. Regions can support multiple availability zones which are physically separated from each other and can also help achieve high availability for an application within a region.
Graceful Failover
Graceful failover can be achieved through elastic IP addresses. Elastic IP addresses allow handling of instance or availability zone failures by programmatically remapping public IP addresses to any instance associated with an account. In this way, the traffic of a failed application can be gracefully rerouted.
It is good practice to keep the data as close as possible to the application to reduce access latency. In the cloud, this practice is even more important because of the additional internet latency.
Best Practices
Dynamic Data
- Data generated in the cloud: The application that consumes the data should also be deployed in the cloud so that it can take advantage of in-cloud free data transfer and lower latency.
- Data outside the cloud: If a large quantity of data resides outside of the cloud, it might be cheaper and faster to transfer the data to the cloud first and then perform the computation.
Static Data
If the data is static and does not change often (for example, images, video, audio, PDFs, JS, CSS files), it is advisable to use a Content Delivery Network (CDN) so that the static data is cached at an edge location closer to the end-user (requester), thereby lowering the access latency.
Notes
The data location can reduce the cost of the gigabytes of data transfered. The following are some examples of dynamic data location strategies:
- Data warehouse. It is advisable to move the dataset to the cloud and then perform parallel queries against the dataset.
- Web app. If the web application stores and retrieves data from relational databases, it is advisable to move the database as well as the app server into the cloud all at once.
- E-commerce app. In the case of an e-commerce web application that generates logs and clickstream data, it is advisable to run the log analyzer and reporting engines in the cloud.
Whether requesting, storing or processing data in the cloud. Whenever possible, parallelization and related automation are encouraged. The cloud supports parallel processing in a way that virtualized systems cannot. This is because it can achieve the required computing power by dynamically commissioning (or de-commissioning) VMs using commodity hardware.
Best Practices
Accessing Data
The cloud supports massively parallel operations, when retrieving and accessing data. For example, the operations required to perform analytics on unformatted big data where concurrent processes are used to store or fetch data rather than performing sequential operations (which would be impossible).
Processing Tasks
When processing or executing requests in the cloud, it is even more important to take advantage of parallelization. The following are some examples:
- Web Application. A general best practice is to distribute the incoming requests across multiple asynchronous servers using a load balancer.
- Batch Processing. A master VM can spawn multiple worker VMs that process tasks in parallel (as in the distributed Hadoop framework).
Notes
Wherever possible, the processes of a cloud application should be made thread-safe through a shared-nothing philosophy and leveraging multi-threading.
The cloud operates at its best when an application can combine elasticity and parallelization. For example, an application can do the following:
- Provision, in a few minutes and via simple API calls, a cluster of VM instances.
- Execute parallel tasks to perform a specific job.
- Store the results.
- Terminate all the VM instances.
Administering Cloud Resources
|
When moving to the cloud, a system administrator may not have the ability to specify resources at the level of physical details, as in a virtual environment. For this reason, it is important to understand the concept of abstract resources to be able to handle the actual physical capabilities of the cloud environment and manage them.
Best Practices
An important aspect of using a cloud environment is the ability to use the cloud APIs, the UI or command line tools to automate the deployment process.
An automated and repeatable process will help in reducing errors and facilitate an efficient and scalable update. In fact, automation is essential for scalability to work. This is the area where the cooperation between developers and administrators is crucial if the cloud must operate reliably and effectively.
To automate the deployment process, follow these guidelines:
- Create a library of recipes. These are small and frequently used scripts for installation and configuration.
- Manage the configuration and deployment process by using agents bundled with a VM image.
- Bootstrap the instances. This allows an instance to obtain the necessary resources such as code, script and configuration based on its role and attaches itself to a cluster to perform its function.
Notes
In the last decade a typical business application has evolved from desk-top centric, to client-server, to web services, and on to service oriented architecture (SOA). In this evolution, abstraction of computing resources has become prominent to reduce costs and improve reliability of IT operations.
Abstraction is at the core of the cloud computing paradigm. Within the cloud, organizations can consume shared computing and storage resources rather than building, operating and maintaining infrastructures.
In the traditional enterprise company, application developers may not work closely with the network administrators and network administrators may not have a clue about the application. As a result, several possible optimizations in the network layer and application architecture layer are overlooked. With the cloud, the two roles have merged into one to some extent. When architecting future applications, companies need to encourage more cross-pollination of knowledge between the two roles and understand that they are merging.
In a cloud environment, a system administrator no longer provisions servers, installs software, or wires network devices. Because the underlying infrastructure is programmable, the cloud encourages automation. In this context, the administrator manages the underlying cloud resources while the developer automates server provisioning, software installation, and network “wiring”.
Legitimate concerns about security exist in the cloud shared resources (multitenant) environment. Security must be implemented at every layer of the cloud application architecture.
Best Practices
Protect Data in Transit (“Encrypt Everything”)
- When data is in transit, between a browser and a web server for example, configure Secure Sockets Layer(SSL) on your server instance.
- Create a Virtual Private Cloud (VPC) to use logically isolated resources within the service provider cloud. Connect those resources directly to your own datacenter using industry standard encrypted IPsec Virtual Private Network (VPN) connections
Protect Data at Rest (“Encrypt Everything”)
- Encrypt sensitive data (individual files) prior uploading it to the cloud.
- Encryption depends on the operating system installed on the server instance. A variety of encrypting tools and techniques exist. Select the ones that best satisfy your requirements.
- Protect your data not only from eavesdropping but also from disaster. Take periodic snapshots of your data to ensure it is highly durable and available. You can use the cloud service provider “endless” storage capabilities where the snapshots are incremental.
Secure the Application
Security Groups
A server instance is protected by security groups whose rules specify which incoming network traffic can be delivered to the instance. TCP and UDP ports can be specified as long as ICMP types and codes and source addresses. Security groups provide basic firewall-like protection for running instances.
Software-Based Firewalls (aka. Host-Based Firewalls)
Another way to restrict traffic to a server instance is via software-based firewalls. Windows instances can use the built-in firewall. Linux instances can use netfilter and iptables.
Notes
Physical Security
This is typically handled by the cloud service provider.
Network and Application Security
- This is the responsibility of the developer that uses the cloud service and the application designer
- Tools created by cloud services providers can help to implement basic security
- Best practices as they apply to the business must be followed
Cloud Computing
Cloud computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. The cloud model of computing promotes availability (NIST).
Elasticity
In cloud computing, elasticity is defined as the degree to which a system is able to adapt to workload changes by provisioning and de-provisioning resources in an autonomic manner, such that at each point in time the available resources match the current demand as closely as possible .
Horizontal Scaling
Horizontal scaling, or increasing the number of servers in the cluster, reduces the responsibilities of each server. The capacity of each server does not change, but its load is decreased. Reasons to scale horizontally include increasing I/O concurrency, reducing the load on existing servers, and increasing disk capacity.
Hybrid Cloud
Hybrid Clouds combine both public and private cloud models. With a Hybrid Cloud, service providers can utilize third party cloud providers in a full or partial manner thus increasing the flexibility of computing. The Hybrid cloud environment is capable of providing on-demand, externally provisioned scale. The ability to augment a private cloud with the public cloud can be used to manage any unexpected surges in workload.
Live Migration
Live migration is the relocation of a virtual machine from one physical host to another while continuously powered-up. When properly carried out, this process takes place without any noticeable effect from the point of view of the end user. Live migration allows an administrator to take a virtual machine offline for maintenance or upgrading without subjecting the system’s users to downtime.
Live migration can also be used for load balancing, in which work is shared among computers in order to optimize the utilization of available CPU resources.
REST
The majority cloud services (and related APIs) are designed using an architectural style known as
Representational State Transfer (REST).This style is widely used and is a simpler alternative to SOAP and related Web Services Description Language (WSDL).
Capitalizing on the Web success and based on its semantics, REST formalizes a set of principles by which you can design cloud services to access system’s resources, including how resource states are addressed and transferred over HTTP by a wide range of clients. As first described by Roy Fielding in his seminal thesis Architectural Styles and the Design of Network-based Software Architectures, REST is a set of software architectural principles that use the Web as a platform for distributed computing . Since then, REST has emerged as the predominant Web service design model.
Scalability
It is the ability of a system, network, or process to handle a growing amount of work in a capable manner or its ability to be enlarged to accommodate that growth. For example, it can refer to the capability of a system to increase its total output under an increased load when resources (typically hardware) are added.
Private Cloud
Private clouds are built exclusively for a single enterprise. They aim to address concerns on data security and offer greater control, which is typically lacking in a public cloud. There are two variations to a private cloud:
- On-premise Private Cloud. On-premise private clouds, also known as internal clouds are hosted within an organization’s own data center. This model provides a more standardized process and protection, but is limited in aspects of size and scalability. IT departments would also need to incur the capital and operational costs for the physical resources. This is best suited for applications which require complete control and configurability of the infrastructure and security.
- Externally hosted Private Cloud. This type of private cloud is hosted externally with a cloud provider, where the provider facilitates an exclusive cloud environment with full guarantee of privacy. This is best suited for enterprises that don’t prefer a public cloud due to sharing of physical resources.
Public Cloud
Public clouds are owned and operated by third parties; they deliver superior economies of scale to customers, as the infrastructure costs are spread among a mix of users, giving each individual client an attractive low-cost, “Pay-as-you-go” model. All customers share the same infrastructure pool with limited configuration, security protections, and availability variances. These are managed and supported by the cloud provider. One of the advantages of a Public cloud is that they may be larger than an enterprises cloud, thus providing the ability to scale seamlessly, on demand.
Virtual Machine
A virtual machine (VM) is a software implementation of a computing environment in which an operating system or program can be installed and run.
The virtual machine typically emulates a physical computing environment, but requests for CPU, memory, hard disk, network and other hardware resources are managed by a virtualization layer which translates these requests to the underlying physical hardware.
VMs are created within a virtualization layer, such as a hypervisor or a virtualization platform that runs on top of a client or server operating system. This operating system is known as the host OS. The virtualization layer can be used to create many individual, isolated VM environments.
Vertical Scaling
Vertical scaling gives greater capacity (CPUs, memory and so on) to a server but does not decrease its overall load. Reasons to scale vertically include increasing IOPS, increasing CPU/RAM capacity, and increasing disk capacity.
Virtualization
Virtualization refers to the creation of a virtual resource such as a server, desktop, operating system, file, storage or network. The main goal of virtualization is to manage workloads by radically transforming traditional computing to make it more scalable. Virtualization has been a part of the IT landscape for decades now, and today it can be applied to a wide range of system layers, including operating system-level virtualization, hardware-level virtualization and server virtualization.
- Virtualization versus Cloud
- Architectural Styles and the Design of Network-based Software Architectures
- Cloud and Virtualization
- Elasticity
- Elasticity in Cloud Computing: What It Is and What It Is Not
- Amazon Elastic Compute Cloud (Amazon EC2)
- Elastic Cloud Infrastructure (OpenStack)
- Scalability
- Designing and Deploying Internet-Scale Services
- Building Scalable Databases
- How To Design a Scalable Cloud Application
- What is Auto Scaling?
- Failure Handling
- Amazon RDS Multi-AZ Deployments
- Designing and Deploying Internet-Scale Services
- Amazon EC2 Elastic IP Addresses
- Data Location
- AWS Import/Export
- Sneakernet
- Parallel Processing
- Hadoop
- Mapreduce
- Cloud Architectures
- Administering Cloud Resources
- Administering and Monitoring an IaaS Cloud
- Scalr Administrator Reference
- 3 Tier Web Application Deployment
- Security
- AWS Security Whitepaper
- The Encrypting File System
- How to Keep AWS Credentials
- Escaping Restrictive Untrusted Networks





 icon in the upper right corner of Eclipse. From the pop-up menu select PyDev and click OK.
icon in the upper right corner of Eclipse. From the pop-up menu select PyDev and click OK.