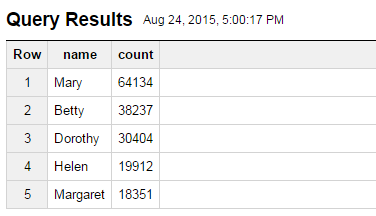
BigQuery is a big data analytics service that is hosted on the Google Cloud Platform. You can analyze large datasets by simply loading data into BigQuery and then executing SQL like queries to gain analytic insights on your data. For more information, see Loading Data Into BigQuery and Query Reference.
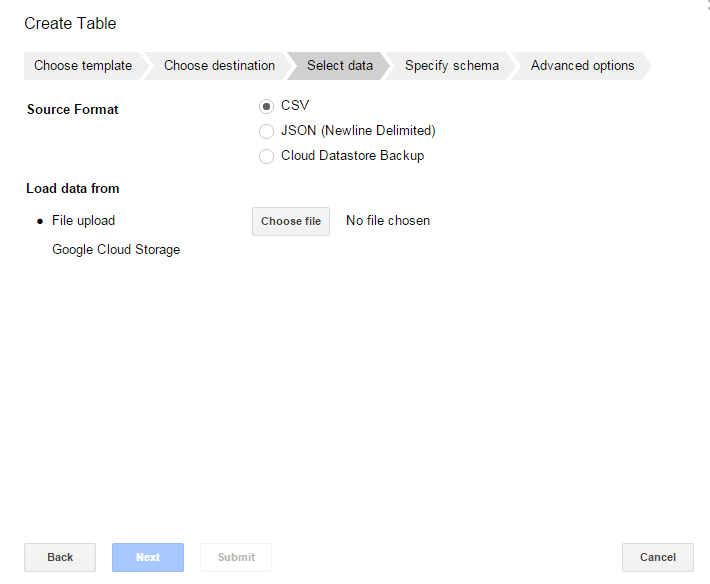
You can load data directly from your workstation but you will be limited in the size of the files to upload. A preferred way is to use Google Cloud Storage as a staging area where you can take full advantage of the service capabilities such as unlimited file size, data replication, backup and so on. For example, you can use Cloud Storage to store historical log data and then take snapshots of this data to load into BigQuery for analytical purposes. BigQuery is integrated seamlessly with Google Cloud Storage as we’ll see in the example section.

Google Cloud Storage is typically used to store raw data before uploading it into BigQuery, this way you can always have access to this data if you want to reload, mashup and so on. You can also export BigQuery data to Google Cloud Storage; for more information, see Exporting Data From BigQuery.
You can access BigQuery in one of the following ways:
- BigQuery browser interface that you can use to import and export data, run queries, and perform other user and management tasks using the browser. For more information, see BigQuery Browser.
- Command line tool (bq) tool that you can use to perform BigQuery operations from the command line. For more information, see Command-line Tool.
- BigQuery API. RESTful API that you can use to access BigQuery programmatically from your application. For more information, see API Reference.
Third-party tools are also available for loading, transforming and visualizing data. For more information, see Third-party Tools.
BigQuery Terms
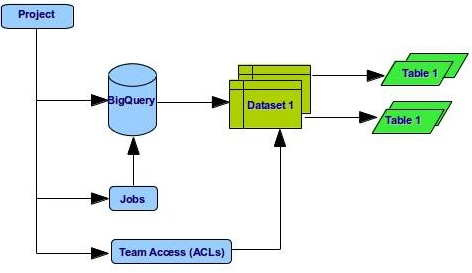
Google Cloud Platform uses a project-centric design. Most functionality will be tied to the project. Components of a project (called “services”) will be able to hold budgets and Access Control Lists (ACLs), for example. The following is a brief description of the terminology you should be familiar with while using BigQuery and Google Cloud Storage.
- Projects. All data in BigQuery belongs inside a project. A project consists of a set of users, a set of APIs, billing, Access Control Lists (ACLs) that determine access to the Datasets and the Jobs, and monitoring settings for those APIs. You can have one project or multiple projects. Projects are created and managed using the Google APIs Console. For information about the related API type, see Projects.
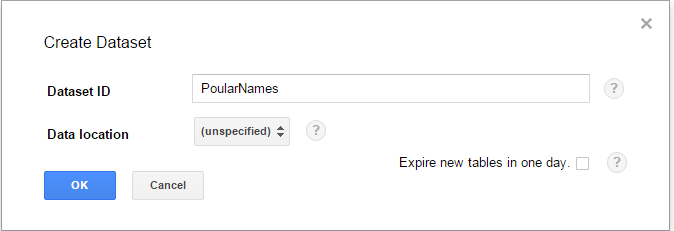
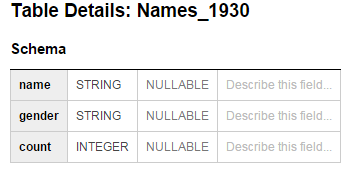
- Datasets. A dataset is a grouping mechanism that holds zero or more tables. A dataset is the lowest level unit of access control. You cannot control access at the table level. A dataset is contained within a specific project. Each dataset can be shared with individual users. Datasets are also referenced in the SQL statements when interacting with BigQuery. For information about the related API type, see Datasets.
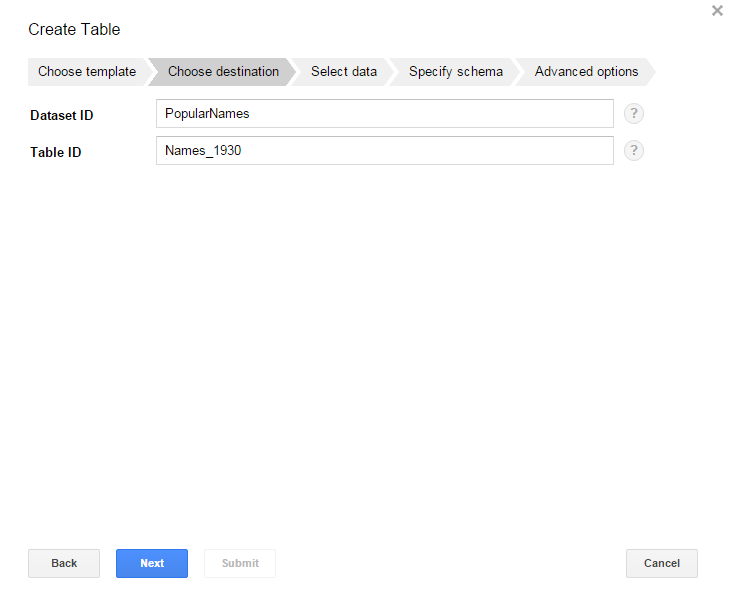
- Tables. Row-column structures that contain actual data. They belong to a Dataset. You query the data at the table-level, but you cannot control access at this level, you do it at the Dataset level. For information about the related API type, see Tables.
- Jobs. Job are is a mechanism by which to schedule tasks such as query, loading data, exporting data. Usually a job is used to start potentially long-running tasks. Shorter tasks, such as list or get requests, are not managed by a job resource. For information about the related API type, see Jobs.
For more information, see Overview and Managing Jobs, Datasets and Projects.