
Amazon Elastic MapReduce (Amazon EMR) is a web service that makes it easy to quickly and cost-effectively process vast amounts of data. Amazon EMR simplifies big data processing, providing a managed Hadoop framework that makes it easy, fast, and cost-effective for you to distribute and process vast amounts of data across dynamically scalable Amazon EC2 instances.You can also run other popular distributed frameworks such as Apache Spark and Presto (SQL Query Engine) in Amazon EMR, and interact with data in other AWS data stores such as Amazon S3 and Amazon DynamoDB. For a quick overview, see Introduction to Amazon Elastic MapReduce.
Background
Amazon EMR enables you to quickly and easily provision as much computing capability as you need and add or reduce or remove it at any time. This is very important when dealing with variable or unpredictable processing requirements as it is often the case with big data processing.
For example, if the bulk of your processing occurs at night, you might need 100 virtual machine instances during the day and 500 instances at night. Or you might need a significant computing peak for a short period of time. With Amazon EMR you can quickly provision hundreds or thousands of instances, and release them when the work is completed. saving on the overall cost.
Computing Capacity
The following are some possible way to control computing capacity:
- Deploy Multiple Clusters. If you need more capacity, you can easily launch a new cluster and terminate it when you no longer need it. There is no limit to how many clusters you can have. Use multiple clusters to accommodate multiple users or applications. For example, you can store your input data in Amazon S3 and launch one cluster for each application that needs to process the data. One cluster might be optimized for CPU, a second cluster might be optimized for storage, etc.

- Resize Running Cluster. With Amazon EMR it is easy to resize a running cluster. You may want to resize a cluster to temporarily add more processing power to the cluster, or shrink it to save on costs. You could add hundreds of instances to the cluster when a batch processing occurs, and remove the extra instances when the processing is completed. When adding instances to your cluster, EMR can start utilizing provisioned capacity as soon it becomes available and you can shrink the cluster with minimum impact to running jobs. For more information, see resize running cluster.
Cost
Amazon EMR is designed to reduce the cost of processing large amounts of data. The following are some of the features to control operational costs:
- Low Hourly Price. Pricing is per instance hour and starts at $.015 per instance hour for a small instance ($131.40 per year). For more information, see Amazon EMR Pricing.
- Amazon EC2 Reserved Instance Integration. Amazon EC2 reserved Instances enable you to maintain the benefits of elastic computing while lowering costs and reserving capacity. With reserved Instances you pay a low, one-time fee and in turn receive a significant discount on the hourly charge for that instance. Amazon EMR makes it easy to utilize reserved Instances so you can save up to 65% off the on-demand price. For more information, see Ensure Capacity with Reserved Instances.
- Elasticity. Amazon EMR makes it easy to add and remove computing power as a result you do not need to provision more capacity than what required. You may not know how much data your cluster(s) must handle in 6 months, or you may have peaks in processing needs. You can easily add or remove capacity at any time.
- S3 Integration. EMR clusters efficiently and securely use Amazon S3 as an object store for Hadoop through its EMR File System (EMRFS). You can store your data in Amazon S3 and use multiple Amazon EMR clusters to process the same data set. Each cluster can be optimized for a particular workload, which can be more efficient than a single cluster serving multiple workloads with different requirements. For example, you might have one cluster that is optimized for I/O and another that is optimized for CPU, each processing the same data set in Amazon S3. In addition, by storing your input and output data in Amazon S3, you can shut down clusters when they are no longer needed.
Data Stores
Amazon EMR allows you to use different types of data stores as described next.
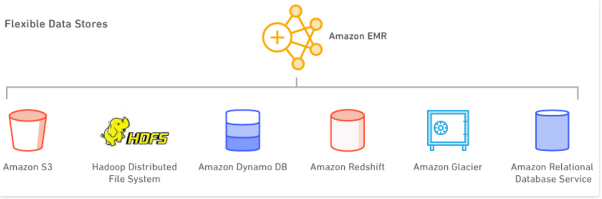
- Amazon S3.Through the EMR File System (EMRFS). Amazon EMRcan efficiently and securely use Amazon S3 as an object store for Hadoop. When you launch your cluster, Amazon EMR streams the data from Amazon S3 to each instance in your cluster and begins processing it immediately. One advantage of storing your data in Amazon S3 and processing it with Amazon EMR is you can use multiple clusters to process the same data. For example, you might have a Hive development cluster that is optimized for memory and a Pig production cluster that is optimized for CPU both using the same input data set.
- Hadoop Distributed File System (HDFS). This is the Hadoop file system. In Amazon EMR, HDFS uses local ephemeral storage. Depending on the instance type, this could be spinning disks or solid state drives. Every instance in your cluster has local ephemeral storage, but you decide which instances run HDFS. Amazon EMR refers to instances running HDFS as core nodes and instances not running HDFS as task nodes. For more information, see Hadoop Distributed File System.
- Amazon DynamoDB. Amazon EMR has direct integration with Amazon DynamoDB which is a fast, fully managed NoSQL database service. You can quickly and efficiently process data stored in Amazon DynamoDB and transfer data between Amazon DynamoDB, Amazon S3, and HDFS in Amazon EMR. For more information, see Amazon DynamoDB
Hadoop Tools
Amazon EMR supports proven Hadoop tools such as Hive, Pig, HBase, and Impala. Additionally, it can run distributed computing frameworks besides Hadoop MapReduce such as Spark or Presto using bootstrap actions. You can also use Hue and Zeppelin as GUIs for interacting with applications on your cluster.

- Hive. Open source data warehouse and analytics package that runs on top of Hadoop.. Hive is operated by Hive QL, a SQL-based language which allows users to structure, summarize, and query data. Hive QL goes beyond standard SQL by adding first-class support for map/reduce functions and complex extensible user-defined data types like JSON and Thrift.This capability allows processing of complex and unstructured data sources such as text documents and log files.Hive allows user extensions via user-defined functions written in Java.
Amazon EMR has made numerous improvements to Hive, including direct integration with Amazon DynamoDB and Amazon S3. For example, you can load table partitions automatically from Amazon S3, you can write data to tables in Amazon S3 without using temporary files, and you can access resources in Amazon S3 such as scripts for custom map/reduce operations and additional libraries. For more information, see Apache Hive. - Pig. Open source analytics package that runs on top of Hadoop. Pig is operated by Pig Latin, a SQL-like language which allows users to structure, summarize, and query data. Pig Latin also adds first-class support for map/reduce functions and complex extensible user defined data types.This capability allows processing of complex and unstructured data sources such as text documents and log files. Pig allows user extensions via user-defined functions written in Java.
Amazon EMR has made numerous improvements to Pig, including the ability to use multiple file systems (normally Pig can only access one remote file system), the ability to load customer JARs and scripts from Amazon S3 and additional functionality for String and DateTime processing. For more information, see Apache Pig. - HBase. Open source, non-relational, distributed database modeled after Google’s BigTable. It runs on top of Hadoop Distributed File System (HDFS) to provide BigTable-like capabilities for Hadoop. HBase provides a fault-tolerant, efficient way of storing large quantities of sparse data using column-based compression and storage. In addition, HBase provides fast lookup of data because data is stored in-memory instead of on disk. HBase is optimized for sequential write operations, and it is highly efficient for batch inserts, updates, and deletes. HBase works seamlessly with Hadoop, sharing its file system and serving as a direct input and output to Hadoop jobs. HBase also integrates with Apache Hive, enabling SQL-like queries over HBase tables, joins with Hive-based tables, and support for Java Database Connectivity (JDBC).
In Amazon EMR, you can back up HBase to Amazon S3 (full or incremental, manual or automated) and you can restore from a previously created backup. For more information, see Apache HBase. - Impala. Open source tool in the Hadoop ecosystem for interactive, ad hoc querying using SQL syntax. Instead of using MapReduce, it leverages a massively parallel processing (MPP) engine similar to that found in traditional relational database management systems (RDBMS). With this architecture, you can query your data in HDFS or HBase tables very quickly, and leverage Hadoop’s ability to process diverse data types and provide schema at runtime.This allows for interactive, low-latency analytics. Also, it supports user defined functions in Java and C++, and can connect to BI tools through ODBC and JDBC drivers. Impala uses the Hive metastore to hold information about the input data, including the partition names and data types.For more information, see Impala
- Hue. Open source user interface for Hadoop that makes it easier to run and develop Hive queries, manage files in HDFS, run and develop Pig scripts, and manage tables.
In Amazon EMR, Hue is integrated with Amazon S3, so you can query directly against S3 and easily transfer files between HDFS and Amazon S3. For more information, see Hue - Spark. Hadoop engine for fast processing of large data sets. It uses in-memory, fault-tolerant resilient distributed data sets (RDDs) and directed, acyclic graphs (DAGs) to define data transformations. Spark also includes Spark SQL, Spark Streaming, MLlib, and GraphX. For more information, see Apache Spark on Amazon EMR.
- Presto. Open-source distributed SQL query engine optimized for low-latency, ad-hoc analysis of data. It supports the ANSI SQL standard, including complex queries, aggregations, joins, and window functions. Presto can process data from multiple data sources including the Hadoop Distributed File System (HDFS) and Amazon S3. For more information, see Presto on Amazon EMR.
- Zeppelin. Open source GUI which creates interactive and collaborative notebooks for data exploration using Spark. You can use Scala, Python, SQL (using Spark SQL), or HiveQL to manipulate data and quickly visualize results. Zeppelin notebooks can be shared among several users, and visualizations can be published to external dashboards. For more information, see Amazon EMR Sandbox Applications.
- Oozie. Workflow scheduler for Hadoop, where you can create Directed Acyclic Graphs (DAGs) of actions. Also, you can easily trigger your Hadoop workflows by actions or time. For more information, see Amazon EMR Sandbox Applications.
- Other. EMR supports a variety of other popular applications and tools, such as R, Mahout (machine learning), Ganglia (monitoring), Accumulo (secure NoSQL database), Sqoop (relational database connector), HCatalog (table and storage management), and more.
The Amazon EMR team maintains an open source repository of bootstrap actions on github that you can use to install additional software, configure your cluster, or serve as examples for writing your own bootstrap actions.
References
- Big Data Definition
- Amazon Elastic Mapreduce (EMR)
- Getting Started: Analyzing Big Data with Amazon EMR
- Getting Started with Amazon EMR
- A Technical Introduction to Amazon Elastic MapReduce

- Amazon EMR Deep Dive and Best Practices
- Amazon S3
- Amazon DynamoDB
- Hadoop
- Apache Spark
- Apache Hive
- Apache Pig
- Apache HBase.
- Apache Impala (incubating)
- Hue
- Presto
- Apache Zeppelin (incubating).
- Apache Oozie Workflow Scheduler for Hadoop