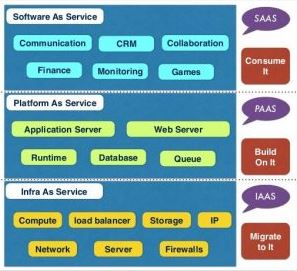
At the core of a cloud service oriented architecture, the Representational State Transfer (REST) APIs play a key role by allowing applications to interact with any of the cloud service types (IaaS, PaaS, or Saas). These APIs abstract out the infrastructure and protocol details and allow any application to communicate with the selected service.
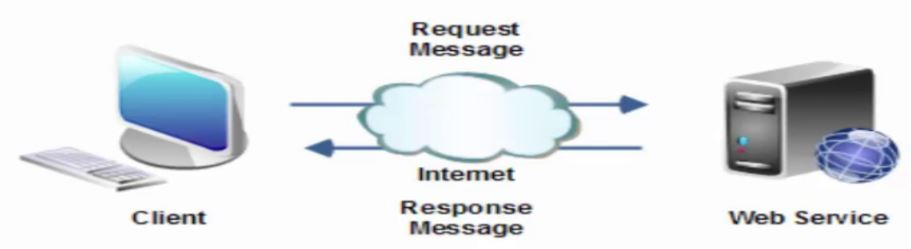
To use these APIs effectively, you must understand the principles on which they are built. To this end, when you think cloud, you must think Web and the underlying protocol used to exchange information. We are all familiar with accessing a page on the Web using a browser. Well, when you access a Web page a request is issued from your computer (client browser) to the Web site (hosting server) using the HTTP protocol.
Representational State Transfer (REST)
The majority of the cloud programming REST APIs are built on the HTTP protocol where the Web is the platform. For more information, see HTTP 1.1 rfc 2616.
More specifically, the majority of the cloud services (and related APIs) are designed using an architectural style known as Representational State Transfer (REST). This style is widely used and is a simpler alternative to SOAP and related Web Services Description Language (WSDL).
Capitalizing on the Web success and based on its semantics, REST formalizes a set of principles by which you can design cloud services to access system’s resources, including how resource states are addressed and transferred over HTTP by a wide range of clients. As first described by Roy Fielding in his seminal thesis Architectural Styles and the Design of Network-based Software Architectures, REST is a set of software architectural principles that use the Web as a platform for distributed computing. Since then, REST has emerged as the predominant Web service design model.
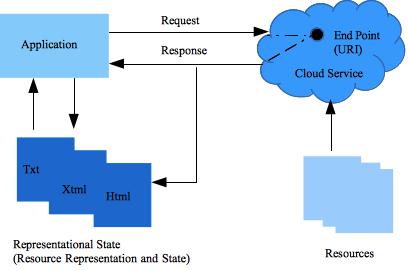
The Web is composed of resources. A resource is any item worth to be exposed. For example, the Sunshine Bakery Inc. may define a chocolate truffle croissant resource. Clients may access that resource with this URL:
http://www.sunshinebakery.com/croissants/croissant/chocolate-truffle
A representation of the resource is returned for example, croissant-chocolate-truffle.html. The representation places the client application in a state. If the client traverses a hyperlink in the page, the new representation places the client application into another state. As a result, the client application changes (transfers) state with each resource representation
Proper Use of HTTP Methods
A key design principle of a RESTful service is the proper use of HTTP methods that follows the protocol as defined in the RFC 2616.
For example, HTTP GET is a data-producing method that is intended to be used by a client to perform one of the following operations:
- Retrieve a resource.
- Obtain data from a Web service.
- Execute a query with the expectation that the Web service will look for and respond with a set of matching resources.
REST guidelines instruct the developers to use HTTP methods explicitly and in a way that is consistent with the protocol definition. This means a one-to-one mapping between create, read, update, and delete (CRUD) operations and HTTP methods as follows:
- Retrieve a resource with GET.
- Create a resource on the service with POST.
- Update a resource with PUT.
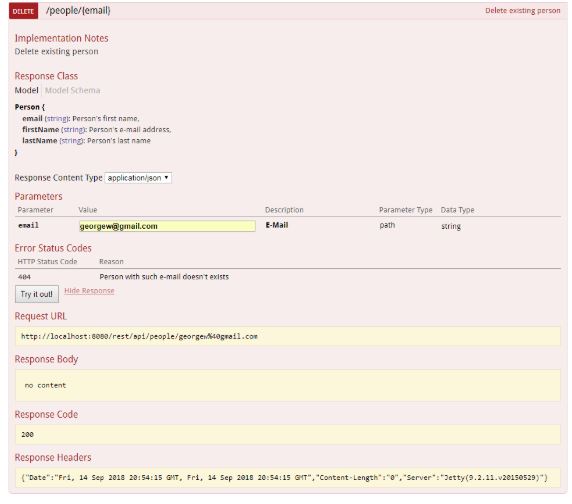
- Remove a resource with DELETE.
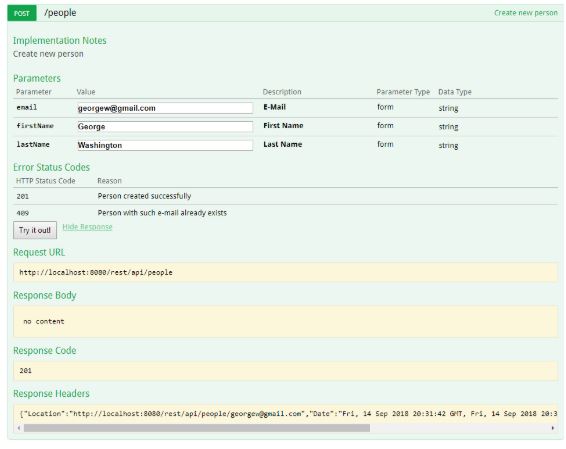
Create a Resource (POST)
The correct way to create a resource is by using the HTTP POST method. All the parameter names and values are contained in XML tags. The payload, an XML representation of the entity to create, is sent in the body of an HTTP POST whose request URI is the intended parent of the entity as shown in the next example.
POST /croissant HTTP/1.1
Host: myserver
Content-Type: application/xml
<?xml version="1.0"?>
<croissant>
<name>chocolate-truffle</name>
</croissant>
The previous example shows a correct RESTful request which uses HTTP POST and includes the payload in the body of the request.
On the service, the request may be processed by adding the resource contained in the body as a subordinate of the resource identified in the request URI; in this case the new resource should be added as a child of /croissants. This containment relationship between the new entity and its parent, as specified in the POST request, is analogous to the way a file is subordinate to its parent directory. The client sets up the relationship between the entity and its parent and defines the new entity’s URI in the POST request.
For more information, see When to use POST.
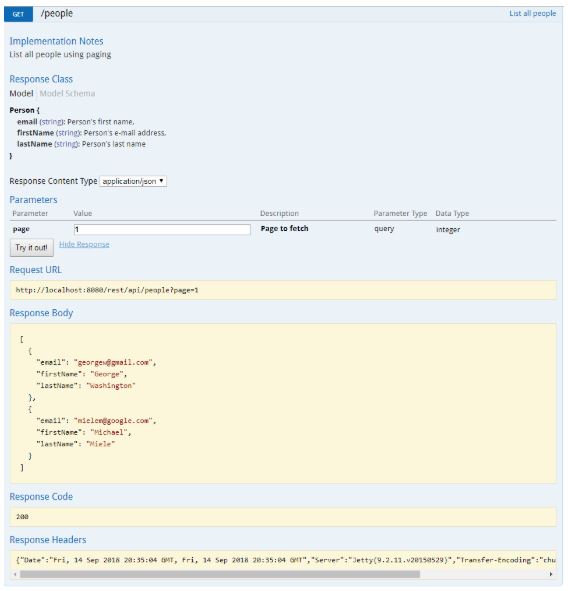
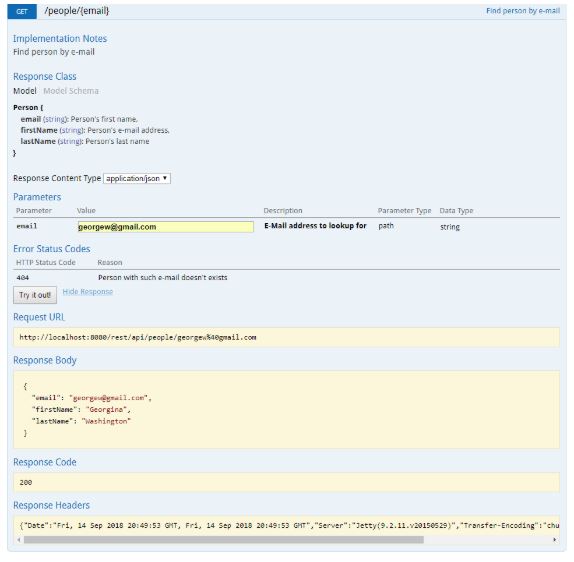
Retrieve a Resource (GET)
A client application may get a representation of the resource (chocolate-truffle) using the URI, noting that at least logically the resource is located under /croissant, as shown in the next GET request.
GET /croissant/chocolate-truffle HTTP/1.1
Host: myserver
Accept: application/xml
This is an explicit use of GET which is for data retrieval only. GET is an operation that must be free of side effects, this property is also known as idempotence.
For more information, see When to use GET.
Warning
Some APIs use GET to trigger transactions on the server for example, to add records to a database. In these cases the GET request URI is not used properly as shown next:
GET /addcroissant?name=chocolate-truffle HTTP/1.1
This is an incorrect design because GET request has side effects. If successfully processed, the result of the request is to add a new croissant type to the data store. The following are the problems with this design:
-
Semantic problem. Cloud services are designed to respond to HTTP GET requests by retrieving resources that match the path (or the query criteria) in the request URI and return a representation in a response, not to add a record to the database. This is an incorrect use of GET that is not compliant with of HTTP/1.1 protocol, using GET.
-
Unintentional side effects. By triggering a change in the server-side state, could unintentionally allow Web caching tools (crawlers) and search engines to make server-side changes simply by crawling a link.
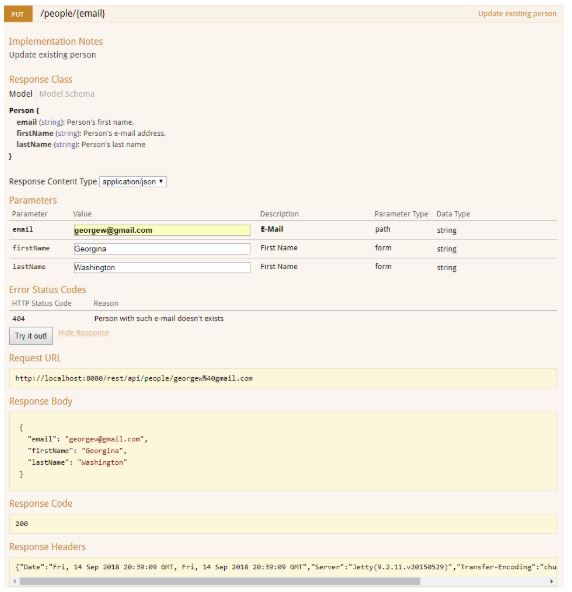
Update a Resource (PUT)
You use HTTP PUT request to update the resource, as shown in the following example:
PUT /croissant HTTP/1.1
Host: myserver
Content-Type: application/xml
<?xml version="1.0"?>
<croissant>
<name>chocolate-truffle</name>
</croissant>
The use of PUT to update the original resource provides a clean interface consistent with the definition of HTTP methods. The PUT request is proper for the following reasons:
- It identifies the resource to update in the URI.
- The client transfers a new representation of the resource in the body of the request.
For more information, see When to use PUT.
See also Representational State Transfer (REST) APIs Part 2 of 4.
References