
To perform the steps described in this section, you must own or have access to a Google Cloud Platform project with BigQuery API enabled. You need credentials to access APIs.
Enable the APIs you plan to use and then create the credentials they require. Depending on the API, you need an API key, a service account, or an OAuth 2.0 client ID. Refer to the API documentation for details. For more information, see Google Cloud API Common Tasks.
Prerequisites
Prepare and load the sample data.
- Obtain the data. The US Government keeps a record of names given to newborn babies for each year going back to 1880. You can download the data from Popular Baby Names. The zip archive contain several comma separated value (CSV) files (one for each year). The file names are in the format “yobNNNN.txt”. You can choose any file you like. For this example we’ll use the file yob2010.txt that contains the most popular names for the year 2010.
- Unzip the archive. The format for each CSV file is name, gender, count. Where gender is either “M” or “F”, and count is the number of children given that name. Remember this format, because you will use it for the schema when you create your table.
NoteThe sample data is already in comma separated value (CSV) format. One of the formats accepted by BigQuery, the other being JSON. So no data preparation is required before loading it into BigQuery.
Create a Dataset
- Launch the Big Query Browser.
- In the left panel, select your project.
- Next to your project name, click the down arrow .
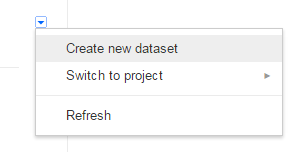
- In the popup menu, click Create new dataset.
- In the dialog box, for the Dataset ID enter the name of the dataset, for example: PopularNames.
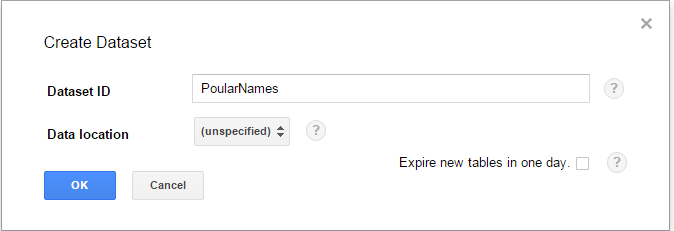
- Click OK.
The new dataset is created and listed under the project in the left panel.
Create and Populate a Table
Now. let’s create the table to hold the data we want to query.
- Click the arrow icon on the right side of the name of the dataset just created.
- In the popup menu, click Create new table. A wizard dialog window is displayed.
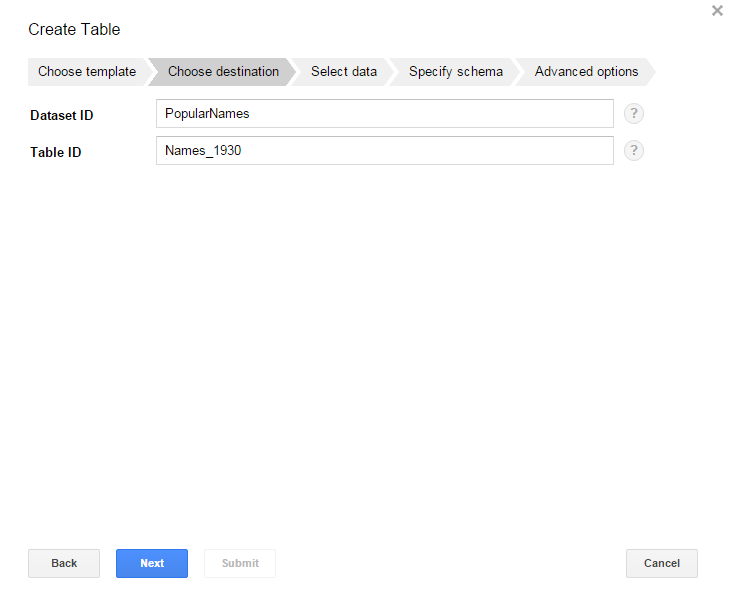
- In the next dialog window, in the Table ID box enter the name of the table. In the picture shown next, the name is Names_1930. Notice that the Dataset ID is PopularNames.
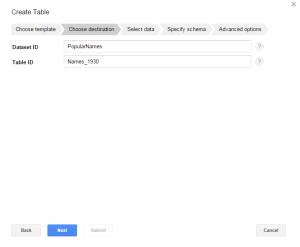
- Click Next.
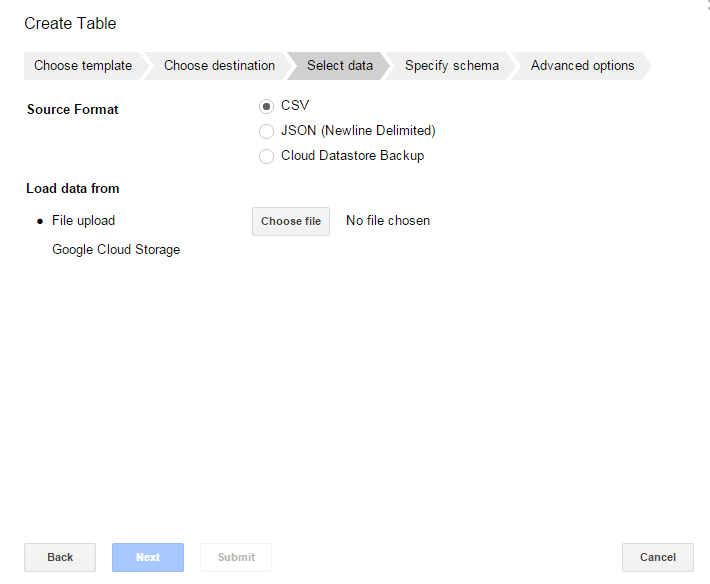
- In the next dialog window, keep the source format CSV selected.
- In the Load data from, click the Choose file button.
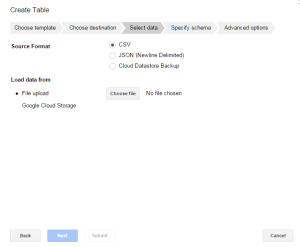
- From your local drive select the file yob1930.txt.
- Click Next.
- In the next dialog window, define the Edit Schema. Click the link Edit as text and enter the following schema: name:string,gender:string,count:integer.
- Click Next.
- In the next dialog window, assure that the field delimiter selection is Comma.
- Click Submit. Wait for the data to load. If the loading is successful you should see the table name Names_1930 displayed under the PopularNames dataset, in the left panel.
Query the Data
Finally, here the rubber hits the road. Let’s query the table we have just populated. .
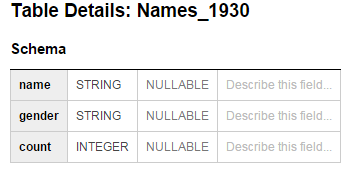
- In the left panel, click the name of the table just created. You will see the schema information displayed in the main panel as shown in the next picture.
- With the Names_1930 table selected, click the Query Table button in the upper right.
- In the New Query box enter the following query:
SELECT name,count FROM PopularNames.Names_1930
WHERE gender = ‘F’ ORDER BY count DESC LIMIT 5; - Click the Run Query button. You should get the following results:
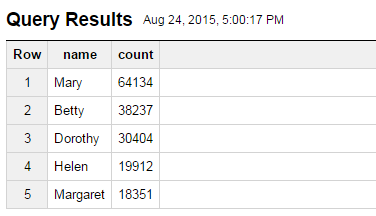
… So Mary was the most popular name for baby girls in the US in the year 1930.