Google Cloud Storage (GCS) is an Infrastructure As Service (IasS) for storing and accessing
customers data. The service combines the performance and scalability of Google’s cloud
with advanced security and sharing capabilities.
GCS provides a simple programming interface through standard HTTP methods PUT, GET,
POST, HEAD, and DELETE to store, share and manage data in the cloud. In this way, you
don’t have to rely on complicated SOAP toolkits or RPC programming.
Google Cloud Storage Architecture
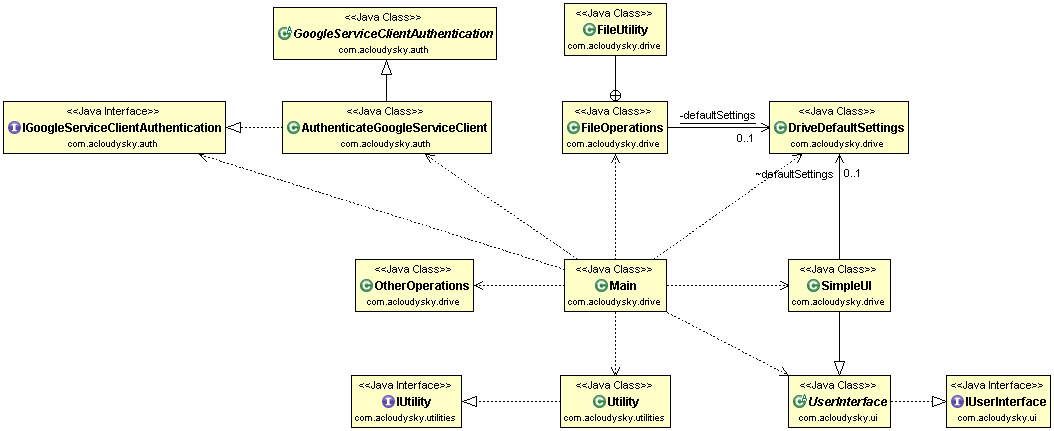
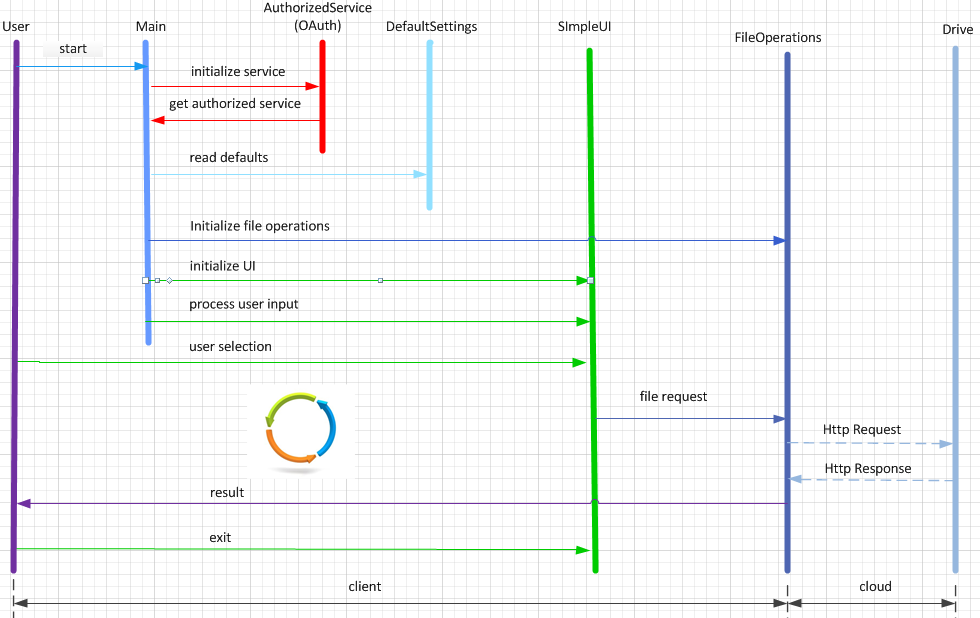
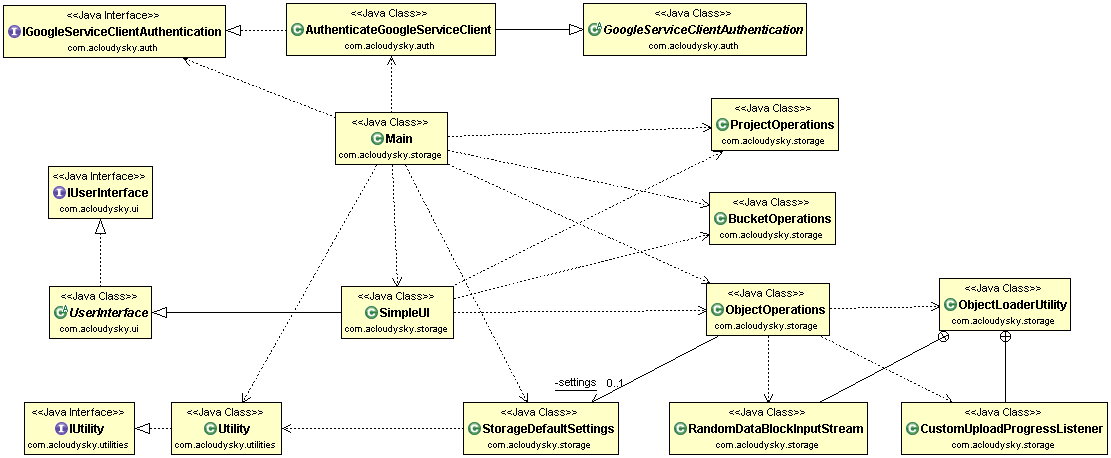
Let’s analyze the GCS main architectural components, as shown in the next figure, to gain
an understanding of GCS inner working and capabilities.
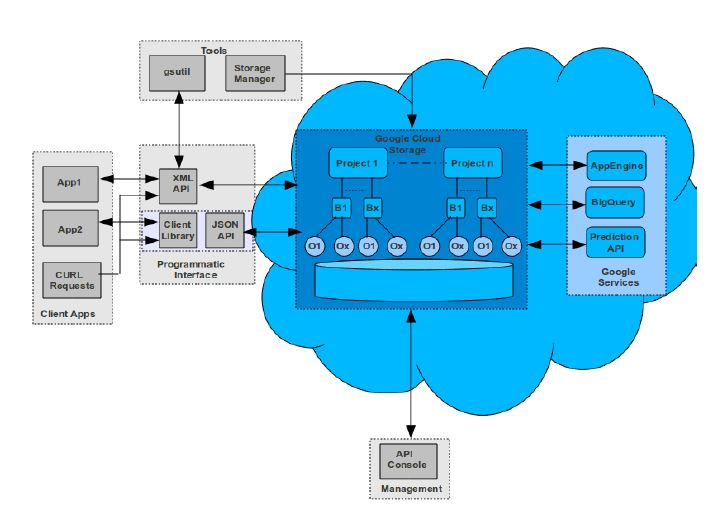
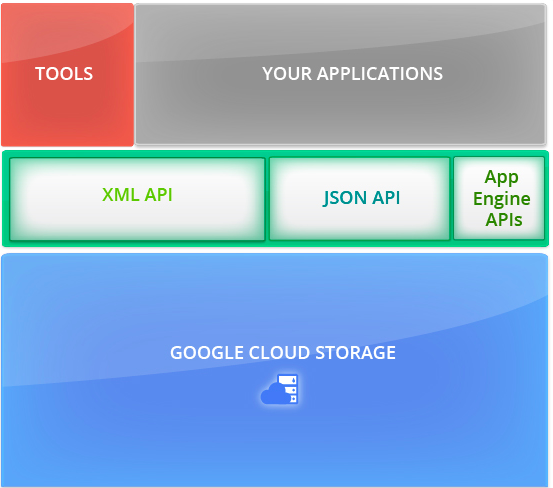
To use Google Cloud Storage effectively you need to understand some of the concepts on
which it is built. These concepts define how your data is stored in Google Cloud Storage.
Projects
All data in Google Cloud Storage belongs inside a project. A project consists of a set
of users, a set of APIs, and billing, authentication, and monitoring settings for those
APIs. You can have one project or multiple projects.
Buckets
Buckets are the basic containers that hold your data. Everything that you store in
Google Cloud Storage must be contained in a bucket. You can use buckets to
organize your data and control access to your data, but unlike directories and
folders, you cannot nest buckets.
- Bucket names. Bucket names must across the entire Google Cloud Storage and have more restrictions than object names because every bucket resides in a single Google Cloud Storage namespace. Also, bucket names can be used with a CNAME redirect, which means they need to conform to DNS naming conventions. For more information, see Bucket and Object Naming Guidelines .
Objects
Objects are the individual pieces of data that you store in Google Cloud Storage. Objects have two components: object data and object metadata . The object data component is usually a file that you want to store in Google Cloud Storage. The object metadata component is a collection of name-value pairs that describe various object qualities.
- Object names. An object name is just metadata to Google Cloud Storage. The following are the main properties:
- An object name can contain any combination of Unicode characters (UTF-8 encoded) less than 1024 bytes in length.
- An object name must be unique within a given bucket.
- A common character to include in file names is a slash (/). By using slashes in an object name, you can make objects appear as though they’re stored in a hierarchical structure. For example, you could name an object /europe/france/paris.jpg and another object /europe/france/cannes.jpg. When you list these objects they appear to be in a hierarchical directory structure based on location; however, Google Cloud Storage sees the objects as independent objects with no hierarchical relationship whatsoever.
- Object Immutability. Objects are immutable, which means that an uploaded object cannot change throughout its storage lifetime. An object’s storage lifetime is the time between successful object creation (upload) and successful object deletion. In practice, this means that you cannot make incremental changes to objects, such as append operations or truncate operations. However, it is possible to overwrite objects that are stored in Google Cloud Storage because an overwrite operation is in effect a delete object operation followed immediately by an upload object operation. So a single overwrite operation simply marks the end of one immutable object’s lifetime and the beginning of a new immutable object’s lifetime.
- Data opacity. An object’s data component is completely opaque to Google Cloud Storage. It is just a chunk of data to Google Cloud Storage.
- Hierarchy. Google Cloud Storage uses a flat hierarchical structure to store buckets and objects. All buckets reside in a single flat hierarchy (you can’t put buckets inside buckets),
and all objects reside in a single flat hierarchy within a given bucket.
- Namespace. There is only one Google Cloud Storage namespace, which means:
- Every bucket must have a unique name across the entire Google Cloud
Storage namespace.
- Object names must be unique only within a given bucket.
Google Cloud Storage Characteristics
When you store your data on Google Cloud Storage, the service does all the background work to make data operations fast so you can focus on your application. The following are the main reasons:
-
GCS is built on Google’s proprietary network and datacenter technology. Google spent several years building proprietary infrastructure and technology to power Google’s sites (after all, fast is better than slow). When you use GCS, the same network goes to work for your data.
-
GCS replicates data to multiple data centers and serves end-user’s requests from the nearest data center that holds a copy of the data. You have a choice of regions (currently U.S. and Europe) to allow you to keep your data close to where it is most needed. Data is also replicated to different disaster zones to ensure high availability.
-
GCS takes the replication one step further. When you upload an object and mark it as cacheable (by setting the standard HTTP Cache-Control header), GCS automatically figures out how best to serve it using Google’s broad network infrastructure, including caching it closer to the end-user if possible.
-
Last but not least, you don’t have to worry about optimizing your storage layout (like you would on a physical disk), or the lookups (i.e. directory and naming structure) like you would on most file systems and some other storage services. GCS takes care of all the “file system” optimizations behind the scenes.
Performance Considerations
When you select a service, one of the most important things to consider is its performance. The performance of a cloud storage service (or any cloud service for that matter) depends on two main factors:
Network
A key performance factor is the network path between the user’s location and the cloud service provider’s data centers. This path is critical because if the network is slow or unreliable, it doesn’t really matter how fast the service is. These are two main ways to make the network faster:
Storage
The other performance factor is how quickly the data center processes a user’s request. This mainly implies the following:
In a way, a cloud storage service is similar to a big distributed file system that performs the following tasks as efficiently as possible:
-
Checks authorization.
-
Locks the object (data) to access.
-
Reads the requested data from the physical storage medium.
-
Transfers data to the user.
For an example of an application using GCS, see Build GCP Cloud Storage Client.