
Overview
The Cloud is a computing model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. For more information, see The NIST Definition of Cloud Computing .
This is a technological breakthrough compared to the traditional approach where resources had to be allocated in advance with the danger of overestimating (or underestimating) the needs.
But, most importantly, in the cloud the allocation is done automatically and in real-time. This is the elasticity attribute of the cloud. The cloud main architectural principle is predicated on delivering IT services on demand. The result is software architectures with qualities such as: elasticity, auto-scaling, fault tolerance and administration automation.
An extension of this is the concept of application as a service usually, a REST web service.For more information about designing for the cloud, see Cloud Ready Design Guidelines .
From a hardware point of view, three aspects are new in cloud computing:
- The “infinite” computing resources available on demand, thereby eliminating the need for users to plan far ahead for provisioning
- The elimination of an up-front commitment by the users, thereby allowing companies to start small and increase hardware resources only when there is an increase in their needs
- The ability to pay for use of computing resources on a short-term basis as needed (e.g., processors by the hour and storage by the day) and release them as needed, thereby rewarding conservation by letting machines and storage go when they are no longer useful.
You may want to take a look at the following video to understand the difference between cloud and traditional virtualization: Cloud and Virtualization.
Cloud Deployment and Service Models
Deployment models define different types of ownership and distribution of the resources used to deliver cloud services to different customers.
Deployment Models
Cloud environments may be deployed over a private infrastructure, public infrastructure, or a combination of both.
The most common deployment models as defined by the National Institute of Standards and Technology (NIST) include the following:
Service Models
Service models identify different control options for the cloud client and cloud provider. For example, SaaS clients simply use the applications and services provided by the provider, where IaaS clients maintain control of their own environment hosted on the provider’s underlying infrastructure. The following are the most commonly used service models:
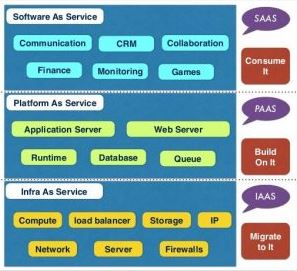
The following picture depicts the service models and the way they stack up:

You can find the above picture and more information at NIST Cloud Computing Reference Architecture.The next picture shows the control and responsibilities for cloud clients and providers across the service models:

Cloud Logical Architecture
The cloud architecture is structured in layers. Each layer abstracts the one below it and exposes interfaces that layers above can build upon. The layers are loosely coupled and provide horizontal scalability (they can expand) if needed. As you can see in the next picture, the layers map to the service models described earlier.

As shown in the previous picture, the cloud architecture contains several layers, as described next.
The vertical bars in the picture represent components that apply to all layers with different degrees of scope and depth. Mainly they support administrative functions, handling of security and cloud programmability (the later supporting the most common programming languages).
